- charset
- encryption
- show
- combinations
- format output
- get lines
xargsfind- trim
- fold
- insert new line
- write a file without indent space
- cat
reference:
charset
[!NOTE|label:references:]
- ASCII Table, ISO 1252 Latin-1 Chart & Character Set
- ASCII Character Chart with Decimal, Binary and Hexadecimal Conversions
- The difference between "binary" and "text" files
- control character
HEX NAME ABBREVIATION ESCAPE CODE 0x00null NUL \0^@0x07bell BEL \a^G0x08backspace BS \b^H0x09horizontal tab HT \t^I0x0aline feed LF \n^J0x0bvertical tab VT \v^K0x0cform feed FF \f^L0x0dcarriage return CR \r^M0x1aControl-Z SUB - ^Z0x1bescape ESC \e^[
list all charset
$ iconv --listconvert text-file from utf-8 to iso-8859-1
$ iconv --from-code=UTF-8 --to-code=ISO-8859-1 inputfile.txt > outputfile.txt
escape
[!NOTE|label:references:]
- Difference between single and double quotes in Bash
- How to escape single quotes within single quoted strings
ESCAPING SEQUENCES COMMENTS \'single quote \"double quote \\backslash \nnew line \thorizontal tab \rcarriage return \?question mark
single quota & double quotas
[!TIP|label:references:]
- 3.1.2.4 ANSI-C Quoting
- 3.1.2.5 Locale-Specific Translation
Prefixing a double-quoted string with a dollar sign (
$), such as$"hello, world", will cause the string to be translated according to the current locale
$ echo $'aa\'bb' aa'bb # ascii code # hex octal hex octal $ echo -e "\x27 \047 \\x22 \042" ' ' " " $ echo -e "Let\x27s get coding!" Let's get coding! $ echo -e "Let\x22s get coding!" Let"s get coding!
encryption
base64
$ echo "marslo" | base64 -w0
bWFyc2xvCg==
- decryption
$ echo "bWFyc2xvCg==" | base64 --decode marslo
show
align
[!NOTE|label:see also]
# right-align
$ printf _"%10s"_ "foobar"
_ foobar_
# left-align
$ printf _"%-10s"_ "foobar"
_foobar _
numfmt
[!NOTE|label:references:]
setup
# generic $ npm install numfmt # osx $ brew install coreutils$ brew list coreutils | grep bin /usr/local/Cellar/coreutils/9.4/bin/md5sum /usr/local/Cellar/coreutils/9.4/bin/gsha512sum /usr/local/Cellar/coreutils/9.4/bin/gusers /usr/local/Cellar/coreutils/9.4/bin/gprintenv /usr/local/Cellar/coreutils/9.4/bin/gmknod /usr/local/Cellar/coreutils/9.4/bin/shuf /usr/local/Cellar/coreutils/9.4/bin/gdd /usr/local/Cellar/coreutils/9.4/bin/gtsort /usr/local/Cellar/coreutils/9.4/bin/grealpath /usr/local/Cellar/coreutils/9.4/bin/grmdir /usr/local/Cellar/coreutils/9.4/bin/gfold /usr/local/Cellar/coreutils/9.4/bin/gnl /usr/local/Cellar/coreutils/9.4/bin/greadlink /usr/local/Cellar/coreutils/9.4/bin/gshred /usr/local/Cellar/coreutils/9.4/bin/gmv /usr/local/Cellar/coreutils/9.4/bin/runcon /usr/local/Cellar/coreutils/9.4/bin/gmkdir /usr/local/Cellar/coreutils/9.4/bin/gkill /usr/local/Cellar/coreutils/9.4/bin/guniq /usr/local/Cellar/coreutils/9.4/bin/gpr /usr/local/Cellar/coreutils/9.4/bin/ptx /usr/local/Cellar/coreutils/9.4/bin/ghead /usr/local/Cellar/coreutils/9.4/bin/glink /usr/local/Cellar/coreutils/9.4/bin/gstat /usr/local/Cellar/coreutils/9.4/bin/gmktemp /usr/local/Cellar/coreutils/9.4/bin/gyes /usr/local/Cellar/coreutils/9.4/bin/gsha1sum /usr/local/Cellar/coreutils/9.4/bin/b2sum /usr/local/Cellar/coreutils/9.4/bin/grm /usr/local/Cellar/coreutils/9.4/bin/gsha256sum /usr/local/Cellar/coreutils/9.4/bin/gfalse /usr/local/Cellar/coreutils/9.4/bin/gwho /usr/local/Cellar/coreutils/9.4/bin/gcut /usr/local/Cellar/coreutils/9.4/bin/gvdir /usr/local/Cellar/coreutils/9.4/bin/gdir /usr/local/Cellar/coreutils/9.4/bin/gchmod /usr/local/Cellar/coreutils/9.4/bin/gbase32 /usr/local/Cellar/coreutils/9.4/bin/sha224sum /usr/local/Cellar/coreutils/9.4/bin/ghostid /usr/local/Cellar/coreutils/9.4/bin/gnohup /usr/local/Cellar/coreutils/9.4/bin/gtr /usr/local/Cellar/coreutils/9.4/bin/gdirname /usr/local/Cellar/coreutils/9.4/bin/gsha384sum /usr/local/Cellar/coreutils/9.4/bin/gchroot /usr/local/Cellar/coreutils/9.4/bin/gpaste /usr/local/Cellar/coreutils/9.4/bin/timeout /usr/local/Cellar/coreutils/9.4/bin/tac /usr/local/Cellar/coreutils/9.4/bin/numfmt /usr/local/Cellar/coreutils/9.4/bin/gid /usr/local/Cellar/coreutils/9.4/bin/gpinky /usr/local/Cellar/coreutils/9.4/bin/genv /usr/local/Cellar/coreutils/9.4/bin/basenc /usr/local/Cellar/coreutils/9.4/bin/nproc /usr/local/Cellar/coreutils/9.4/bin/gln /usr/local/Cellar/coreutils/9.4/bin/gbasename /usr/local/Cellar/coreutils/9.4/bin/gtruncate /usr/local/Cellar/coreutils/9.4/bin/stdbuf /usr/local/Cellar/coreutils/9.4/bin/chcon /usr/local/Cellar/coreutils/9.4/bin/gcp /usr/local/Cellar/coreutils/9.4/bin/gls /usr/local/Cellar/coreutils/9.4/bin/factor /usr/local/Cellar/coreutils/9.4/bin/gtrue /usr/local/Cellar/coreutils/9.4/bin/gchown /usr/local/Cellar/coreutils/9.4/bin/gsync /usr/local/Cellar/coreutils/9.4/bin/guptime /usr/local/Cellar/coreutils/9.4/bin/gsum /usr/local/Cellar/coreutils/9.4/bin/gtac /usr/local/Cellar/coreutils/9.4/bin/gexpand /usr/local/Cellar/coreutils/9.4/bin/gruncon /usr/local/Cellar/coreutils/9.4/bin/gpathchk /usr/local/Cellar/coreutils/9.4/bin/gnice /usr/local/Cellar/coreutils/9.4/bin/gecho /usr/local/Cellar/coreutils/9.4/bin/gdu /usr/local/Cellar/coreutils/9.4/bin/gb2sum /usr/local/Cellar/coreutils/9.4/bin/gtouch /usr/local/Cellar/coreutils/9.4/bin/gmkfifo /usr/local/Cellar/coreutils/9.4/bin/gdf /usr/local/Cellar/coreutils/9.4/bin/gjoin /usr/local/Cellar/coreutils/9.4/bin/gtest /usr/local/Cellar/coreutils/9.4/bin/gmd5sum /usr/local/Cellar/coreutils/9.4/bin/gunexpand /usr/local/Cellar/coreutils/9.4/bin/gsort /usr/local/Cellar/coreutils/9.4/bin/gshuf /usr/local/Cellar/coreutils/9.4/bin/gfmt /usr/local/Cellar/coreutils/9.4/bin/gunlink /usr/local/Cellar/coreutils/9.4/bin/gcsplit /usr/local/Cellar/coreutils/9.4/bin/g[ /usr/local/Cellar/coreutils/9.4/bin/gwhoami /usr/local/Cellar/coreutils/9.4/bin/gsplit /usr/local/Cellar/coreutils/9.4/bin/gseq /usr/local/Cellar/coreutils/9.4/bin/sha1sum /usr/local/Cellar/coreutils/9.4/bin/sha256sum /usr/local/Cellar/coreutils/9.4/bin/gdircolors /usr/local/Cellar/coreutils/9.4/bin/ginstall /usr/local/Cellar/coreutils/9.4/bin/gsha224sum /usr/local/Cellar/coreutils/9.4/bin/shred /usr/local/Cellar/coreutils/9.4/bin/sha384sum /usr/local/Cellar/coreutils/9.4/bin/gcomm /usr/local/Cellar/coreutils/9.4/bin/gtty /usr/local/Cellar/coreutils/9.4/bin/gcksum /usr/local/Cellar/coreutils/9.4/bin/gexpr /usr/local/Cellar/coreutils/9.4/bin/gbase64 /usr/local/Cellar/coreutils/9.4/bin/gwc /usr/local/Cellar/coreutils/9.4/bin/gnproc /usr/local/Cellar/coreutils/9.4/bin/base32 /usr/local/Cellar/coreutils/9.4/bin/gptx /usr/local/Cellar/coreutils/9.4/bin/gtimeout /usr/local/Cellar/coreutils/9.4/bin/pinky /usr/local/Cellar/coreutils/9.4/bin/hostid /usr/local/Cellar/coreutils/9.4/bin/gpwd /usr/local/Cellar/coreutils/9.4/bin/gtail /usr/local/Cellar/coreutils/9.4/bin/gchcon /usr/local/Cellar/coreutils/9.4/bin/glogname /usr/local/Cellar/coreutils/9.4/bin/guname /usr/local/Cellar/coreutils/9.4/bin/gtee /usr/local/Cellar/coreutils/9.4/bin/gstty /usr/local/Cellar/coreutils/9.4/bin/gchgrp /usr/local/Cellar/coreutils/9.4/bin/gcat /usr/local/Cellar/coreutils/9.4/bin/ggroups /usr/local/Cellar/coreutils/9.4/bin/gsleep /usr/local/Cellar/coreutils/9.4/bin/sha512sum /usr/local/Cellar/coreutils/9.4/bin/gfactor /usr/local/Cellar/coreutils/9.4/bin/god /usr/local/Cellar/coreutils/9.4/bin/gprintf /usr/local/Cellar/coreutils/9.4/bin/gstdbuf /usr/local/Cellar/coreutils/9.4/bin/gnumfmt /usr/local/Cellar/coreutils/9.4/bin/gbasenc /usr/local/Cellar/coreutils/9.4/bin/gdate /usr/local/Cellar/coreutils/9.4/libexec/gnubin/tee /usr/local/Cellar/coreutils/9.4/libexec/gnubin/md5sum /usr/local/Cellar/coreutils/9.4/libexec/gnubin/split /usr/local/Cellar/coreutils/9.4/libexec/gnubin/cat /usr/local/Cellar/coreutils/9.4/libexec/gnubin/shuf /usr/local/Cellar/coreutils/9.4/libexec/gnubin/mkfifo /usr/local/Cellar/coreutils/9.4/libexec/gnubin/pathchk /usr/local/Cellar/coreutils/9.4/libexec/gnubin/runcon /usr/local/Cellar/coreutils/9.4/libexec/gnubin/expand /usr/local/Cellar/coreutils/9.4/libexec/gnubin/tty /usr/local/Cellar/coreutils/9.4/libexec/gnubin/basename /usr/local/Cellar/coreutils/9.4/libexec/gnubin/install /usr/local/Cellar/coreutils/9.4/libexec/gnubin/nice /usr/local/Cellar/coreutils/9.4/libexec/gnubin/truncate /usr/local/Cellar/coreutils/9.4/libexec/gnubin/echo /usr/local/Cellar/coreutils/9.4/libexec/gnubin/du /usr/local/Cellar/coreutils/9.4/libexec/gnubin/ptx /usr/local/Cellar/coreutils/9.4/libexec/gnubin/join /usr/local/Cellar/coreutils/9.4/libexec/gnubin/df /usr/local/Cellar/coreutils/9.4/libexec/gnubin/pwd /usr/local/Cellar/coreutils/9.4/libexec/gnubin/test /usr/local/Cellar/coreutils/9.4/libexec/gnubin/csplit /usr/local/Cellar/coreutils/9.4/libexec/gnubin/sort /usr/local/Cellar/coreutils/9.4/libexec/gnubin/whoami /usr/local/Cellar/coreutils/9.4/libexec/gnubin/touch /usr/local/Cellar/coreutils/9.4/libexec/gnubin/unlink /usr/local/Cellar/coreutils/9.4/libexec/gnubin/b2sum /usr/local/Cellar/coreutils/9.4/libexec/gnubin/sleep /usr/local/Cellar/coreutils/9.4/libexec/gnubin/fmt /usr/local/Cellar/coreutils/9.4/libexec/gnubin/stty /usr/local/Cellar/coreutils/9.4/libexec/gnubin/logname /usr/local/Cellar/coreutils/9.4/libexec/gnubin/chgrp /usr/local/Cellar/coreutils/9.4/libexec/gnubin/printenv /usr/local/Cellar/coreutils/9.4/libexec/gnubin/seq /usr/local/Cellar/coreutils/9.4/libexec/gnubin/uname /usr/local/Cellar/coreutils/9.4/libexec/gnubin/sha224sum /usr/local/Cellar/coreutils/9.4/libexec/gnubin/od /usr/local/Cellar/coreutils/9.4/libexec/gnubin/date /usr/local/Cellar/coreutils/9.4/libexec/gnubin/base64 /usr/local/Cellar/coreutils/9.4/libexec/gnubin/realpath /usr/local/Cellar/coreutils/9.4/libexec/gnubin/readlink /usr/local/Cellar/coreutils/9.4/libexec/gnubin/dircolors /usr/local/Cellar/coreutils/9.4/libexec/gnubin/timeout /usr/local/Cellar/coreutils/9.4/libexec/gnubin/tac /usr/local/Cellar/coreutils/9.4/libexec/gnubin/numfmt /usr/local/Cellar/coreutils/9.4/libexec/gnubin/wc /usr/local/Cellar/coreutils/9.4/libexec/gnubin/basenc /usr/local/Cellar/coreutils/9.4/libexec/gnubin/comm /usr/local/Cellar/coreutils/9.4/libexec/gnubin/nproc /usr/local/Cellar/coreutils/9.4/libexec/gnubin/expr /usr/local/Cellar/coreutils/9.4/libexec/gnubin/stdbuf /usr/local/Cellar/coreutils/9.4/libexec/gnubin/cksum /usr/local/Cellar/coreutils/9.4/libexec/gnubin/printf /usr/local/Cellar/coreutils/9.4/libexec/gnubin/groups /usr/local/Cellar/coreutils/9.4/libexec/gnubin/chcon /usr/local/Cellar/coreutils/9.4/libexec/gnubin/factor /usr/local/Cellar/coreutils/9.4/libexec/gnubin/tail /usr/local/Cellar/coreutils/9.4/libexec/gnubin/env /usr/local/Cellar/coreutils/9.4/libexec/gnubin/pr /usr/local/Cellar/coreutils/9.4/libexec/gnubin/head /usr/local/Cellar/coreutils/9.4/libexec/gnubin/kill /usr/local/Cellar/coreutils/9.4/libexec/gnubin/uniq /usr/local/Cellar/coreutils/9.4/libexec/gnubin/stat /usr/local/Cellar/coreutils/9.4/libexec/gnubin/link /usr/local/Cellar/coreutils/9.4/libexec/gnubin/sum /usr/local/Cellar/coreutils/9.4/libexec/gnubin/tsort /usr/local/Cellar/coreutils/9.4/libexec/gnubin/mknod /usr/local/Cellar/coreutils/9.4/libexec/gnubin/users /usr/local/Cellar/coreutils/9.4/libexec/gnubin/dd /usr/local/Cellar/coreutils/9.4/libexec/gnubin/who /usr/local/Cellar/coreutils/9.4/libexec/gnubin/sha1sum /usr/local/Cellar/coreutils/9.4/libexec/gnubin/mktemp /usr/local/Cellar/coreutils/9.4/libexec/gnubin/cut /usr/local/Cellar/coreutils/9.4/libexec/gnubin/sha256sum /usr/local/Cellar/coreutils/9.4/libexec/gnubin/dir /usr/local/Cellar/coreutils/9.4/libexec/gnubin/mkdir /usr/local/Cellar/coreutils/9.4/libexec/gnubin/nl /usr/local/Cellar/coreutils/9.4/libexec/gnubin/shred /usr/local/Cellar/coreutils/9.4/libexec/gnubin/fold /usr/local/Cellar/coreutils/9.4/libexec/gnubin/rmdir /usr/local/Cellar/coreutils/9.4/libexec/gnubin/sha384sum /usr/local/Cellar/coreutils/9.4/libexec/gnubin/mv /usr/local/Cellar/coreutils/9.4/libexec/gnubin/dirname /usr/local/Cellar/coreutils/9.4/libexec/gnubin/id /usr/local/Cellar/coreutils/9.4/libexec/gnubin/base32 /usr/local/Cellar/coreutils/9.4/libexec/gnubin/pinky /usr/local/Cellar/coreutils/9.4/libexec/gnubin/ln /usr/local/Cellar/coreutils/9.4/libexec/gnubin/hostid /usr/local/Cellar/coreutils/9.4/libexec/gnubin/chroot /usr/local/Cellar/coreutils/9.4/libexec/gnubin/ls /usr/local/Cellar/coreutils/9.4/libexec/gnubin/true /usr/local/Cellar/coreutils/9.4/libexec/gnubin/cp /usr/local/Cellar/coreutils/9.4/libexec/gnubin/sync /usr/local/Cellar/coreutils/9.4/libexec/gnubin/yes /usr/local/Cellar/coreutils/9.4/libexec/gnubin/unexpand /usr/local/Cellar/coreutils/9.4/libexec/gnubin/chown /usr/local/Cellar/coreutils/9.4/libexec/gnubin/chmod /usr/local/Cellar/coreutils/9.4/libexec/gnubin/uptime /usr/local/Cellar/coreutils/9.4/libexec/gnubin/rm /usr/local/Cellar/coreutils/9.4/libexec/gnubin/vdir /usr/local/Cellar/coreutils/9.4/libexec/gnubin/false /usr/local/Cellar/coreutils/9.4/libexec/gnubin/sha512sum /usr/local/Cellar/coreutils/9.4/libexec/gnubin/[ /usr/local/Cellar/coreutils/9.4/libexec/gnubin/tr /usr/local/Cellar/coreutils/9.4/libexec/gnubin/paste /usr/local/Cellar/coreutils/9.4/libexec/gnubin/nohupusage
$ bc -l <<< 'obase=2;0;0;15;255' 0 0 1111 11111111 $ bc -l <<< 'obase=2;0;0;15;255' | numfmt --format=%08f 00000000 00000000 00001111 11111111 $ bc -l <<< 'obase=2;0;0;15;255' | numfmt --format=%08f | xargs 00000000 00000000 00001111 11111111 $ numfmt --to=si --format "%f bottles of beer on the wall" 99999999 100M bottles of beer on the wallconvert format
$ echo 1G | numfmt --from=si 1000000000 $ echo 1G | numfmt --from=iec 1073741824 $ echo 500G | numfmt --from=si --to=iec 466G $ numfmt --field=2 --from-unit=1024 --to=iec-i --suffix B < /proc/meminfo | sed 's/ kB//' | head -n4 MemTotal: 1008GiB MemFree: 816GiB MemAvailable: 941GiB Buffers: 3.1MiB $ watch -n.1 \ > 'numfmt --header --field=2 --to=iec-i --round=nearest < /proc/interrupts | > LC_ALL=en_US numfmt --header --field=3 --group --invalid=ignore --padding=16 | > pr -TW$COLUMNS' $ for method in up down nearest; do > echo $method > numfmt --to=iec --round=$method 4095 4096 4097 > done | paste - - - - up 4.0K 4.0K 4.1K down 3.9K 4.0K 4.0K nearest 4.0K 4.0K 4.0Kpadding
$ du -s * | numfmt --to=si --padding=10 12 awk.md 40 character.md 4 html.md 16 json.md 8 markdown.md 4 regex.md 16 sed.md $ du -s * | numfmt --to=si --padding=-10 12 awk.md 40 character.md 4 html.md 16 json.md 8 markdown.md 4 regex.md 16 sed.mdfield
$ ls -l total 100 -rw-r--r-- 1 marslo staff 9720 Sep 7 00:37 awk.md -rw-r--r-- 1 marslo staff 40500 Sep 7 00:51 character.md $ ls -l | numfmt --field 5 --to=si total 100 -rw-r--r-- 1 marslo staff 9.8K Sep 7 00:37 awk.md -rw-r--r-- 1 marslo staff 41K Sep 7 00:51 character.md $ df -B1 | head -3 Filesystem 1B-blocks Used Available Use% Mounted on devtmpfs 540881096704 0 540881096704 0% /dev tmpfs 540899667968 258048 540899409920 1% /dev/shm $ df -B1 | head -3 | numfmt --header --field 2-4 --to=si Filesystem 1B-blocks Used Available Use% Mounted on devtmpfs 541G 0 541G 0% /dev tmpfs 541G 259K 541G 1% /dev/shm
q
[!NOTE|label:references:]
$ git log --author="marslo" --format=tformat: --numstat | q -t "select sum(c1), sum(c2) from -"
60650.0 66363.0
combinations
single line to multiple lines
[!TIP]
$ echo 'a b c' a b c
xargs -n<x>$ echo 'a b c' | xargs -n1 a b c $ echo {a..c}.{1..2} | xargs -n1 | xargs -I{} echo -{}- -a.1- -a.2- -b.1- -b.2- -c.1- -c.2--
$ echo 'a b c' | fmt -1 a b c $ echo {a..c}.{1..2} | fmt -1 | xargs -I{} echo -{}- -a.1- -a.2- -b.1- -b.2- -c.1- -c.2- -
$ echo 'a b c' | awk '{ OFS=RS; $1=$1 }1' a b c tr$ echo 'a b c' | tr -s ' ' '\n' a b c-
$ printf '%s\n' a b c a b c
execute commands from file
-
[!TIP]
- precondition
$ cat a.txt a b c
$ echo 'a b c' | xargs -n1 -t touch touch a touch b touch c $ echo 'a b c' | xargs -n1 -p touch touch a?...y touch b?...y touch c?...y-t, --verbose Print the command line on the standard error output before executing it. -p, --interactive Prompt the user about whether to run each command line and read a line from the terminal. Only run the command line if the response starts with `y' or `Y'. Implies -t. -I replace-str Replace occurrences of replace-str in the initial-arguments with names read from standard in- put. Also, unquoted blanks do not terminate input items; instead the separator is the new- line character. Implies -x and -L 1. - precondition
combine every 2 lines
[!NOTE|label:references:]
- How to merge every two lines into one from the command line?
- Automatic documentation of gitconfig aliases using sed or awk
sample output
$ echo -e "1\na\n2\nb\n3\nc 1 a 2 b 3 calso using for sed output :
$ git --no-pager log -3 --no-color | sed -nr 's!^commit\s*(.+)$!\1!p; s!^\s*Change-Id:\s*(.*$)!\1!p' d9a9adfb591bb129d6b1af9532fea0fcf069b176 I5d99e9ccd4edbba608e7da70e575fd6bd091ce42 7aed870eeb203336e5e29b03714905f28ec3e60d Ie3b4d5fd09a43385a44282a2e6961e220ae6293a 09a652f7c78f416da7a561451ed274f930c27dec I244d2fec5d25e453fd30d08d1c75c16143b7f7a3
xargs
$ echo -e "1\na\n2\nb\n3\nc" | xargs -n2 -d'\n' 1 a 2 b 3 cpaste
$ echo -e "1\na\n2\nb\n3\nc" | paste -s -d',\n' 1,a 2,b 3,c $ echo -e "1\na\n2\nb\n3\nc" | paste -d " " - - 1 a 2 b 3 csed
$ echo -e "1\na\n2\nb\n3\nc" | sed 'N;s/\n/ : /' 1 : a 2 : b 3 : cawk
$ echo -e "1\na\n2\nb\n3\nc" | awk '{ key=$0; getline; print key " : " $0; }' 1 : a 2 : b 3 : c # or $ echo -e "1\na\n2\nb\n3\nc" | awk 'ORS=NR%2?FS:RS' 1 a 2 b 3 c # or $ echo -e "1\na\n2\nb\n3\nc" | awk 'NR%2{ printf "%s : ",$0;next; }1' 1 : a 2 : b 3 : c # or $ echo -e "1\na\n2\nb\n3\nc" | awk '{ if ( NR%2 != 0 ) line=$0; else { printf("%s : %s\n", line, $0); line=""; } } END { if ( length(line) ) print line; }' 1 : a 2 : b 3 : cwhile
$ echo -e "1\na\n2\nb\n3\nc" | while read line1; do read line2; echo "$line1 : $line2"; done 1 : a 2 : b 3 : c
combine every 3 lines
paste
# or every 3 lines $ echo -e "1\na\n2\nb\n3\nc" | paste -d ' ' - - - 1 a 2 b 3 cawk
$ echo -e "1\na\n2\nb\n3\nc" | awk 'NR%3{ printf "%s : ",$0;next; }1' 1 : a : 2 b : 3 : cxargs
$ echo {1..9} | fmt -1 | xargs -n3 1 2 3 4 5 6 7 8 9
format output
[!TIP|label:sample data]
$ paste <(sort a.txt) <(sort b.txt) | expand --tabs=10 a a b b d c f d e $ pr -w 30 -m -t a.txt b.txt a a b b d c f d e
echo
[!TIP]
$ echo -e "a\t\tb"
a b
$ echo -e $(echo -e "a\t\tb")
a b

print file with ansicolor
$ command cat c.txt get get/exec get/subresource list create create/exec get/subresource \e[32;1myes\e[0m \e[32;1myes\e[0m \e[32;1myes\e[0m \e[32;1myes\e[0m \e[32;1myes\e[0m no no $ echo -ne $(command cat c.txt | sed 's/$/\\n/' | sed 's/ /\\a /g') get get/exec get/subresource list create create/exec get/subresource yes yes yes yes yes no no $ echo -ne $(command cat c.txt | sed 's/$/\\n/' | sed 's/ /\\033 /g') get get/exec get/subresource list create create/exec get/subresource yes yes yes yes yes no no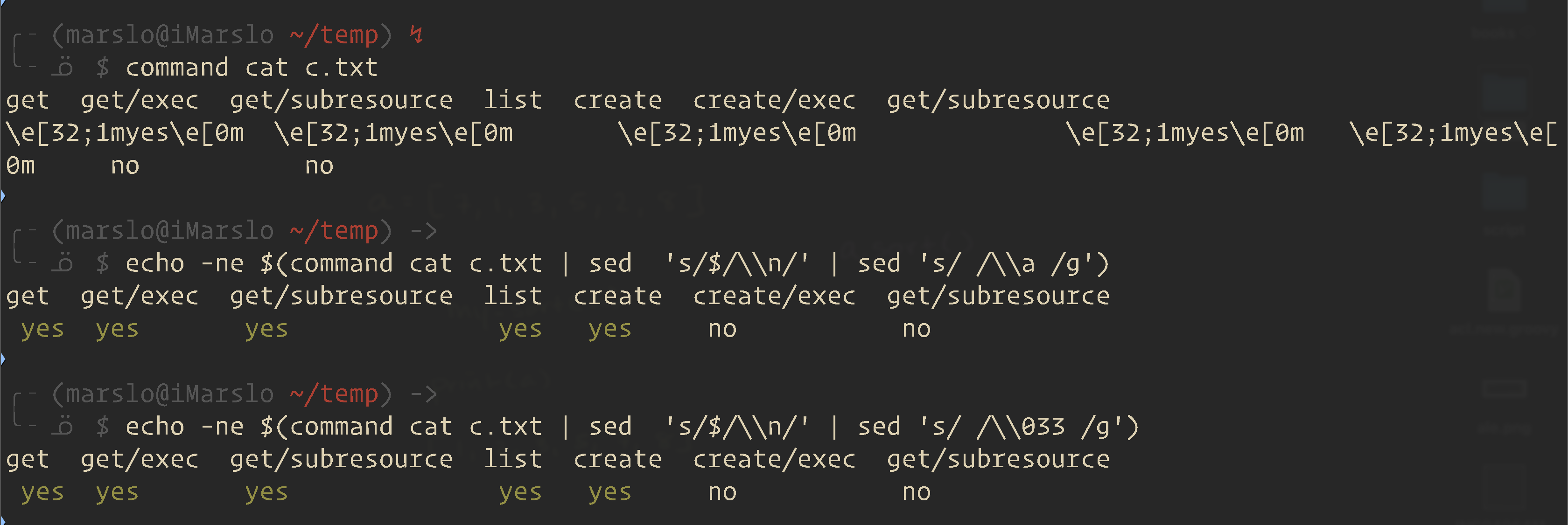
1.2.3.2 -- echo -ne file with ansicolor
diff
[!NOTE|label:references:]
show all status
$ diff --side-by-side <(sort a.txt) <(sort b.txt) a a b b > c d d f | eshow diff only
$ diff --suppress-common-lines --side-by-side <(sort a.txt) <(sort b.txt) > c f | eshow diff with
--<GTYPE>-group-formatVARIABLE APPLICABLE oldGTYPE,LTYPEnewGTYPE,LTYPEunchangedGTYPE,LTYPEchangedGTYPE[!NOTE|label:tips:]
- line format:
[G]TYPE:[g]roup:--<GTYPE>-group-format
- group format
[L]TYPE:[l]ine:--<LTYPE>-line-format
$ diff --old-group-format="L %<" --new-group-format="R %>" --unchanged-group-format="" a.txt b.txt R c L f R e # with line number $ diff --unchanged-line-format="" --old-line-format="< %dn: %L" --new-line-format="> %dn: %L" <(sort a.txt) <(sort b.txt) > 3: c < 4: f > 5: e # beging-end $ diff --old-group-format='\begin{em} -> %<\end{em} -> ' --new-group-format='\begin{bf} -> %>\end{bf} -> ' --changed-group-format='\begin{em} -> %<\end{em} -> \begin{bf} -> %>\end{bf} -> ' --unchanged-group-format='%=' \ -> <(sort a.txt) <(sort b.txt) a b \begin{bf} c \end{bf} d \begin{em} f \end{em} \begin{bf} e \end{bf} $ diff \ -> --unchanged-group-format='' \ -> --old-group-format='-------- %dn line%(n=1?:s) deleted at %df: %<' \ -> --new-group-format='-------- %dN line%(N=1?:s) added after %de: %>' \ -> --changed-group-format='-------- %dn line%(n=1?:s) changed at %df: %<-------- to: %>' \ -> <(sort a.txt) <(sort b.txt) -------- 1 line added after 2: c -------- 1 line changed at 4: f -------- to: e- line format:
show common
$ diff --unchanged-line-format="%L" --new-line-format="" --old-line-format="" <(sort a.txt) <(sort b.txt) a b dcreate patch
[!NOTE|label:references:]
- Is this a good way to create a patch?
$ diff -Naru file_original file_updated > file.patch
$ diff -c <(sort a.txt) <(sort b.txt) *** /dev/fd/63 2023-09-12 21:51:50.828885643 -0700 --- /dev/fd/62 2023-09-12 21:51:50.829641102 -0700 *************** *** 1,4 **** a b d ! f --- 1,5 ---- a b + c d ! e $ diff -u <(sort a.txt) <(sort b.txt) --- /dev/fd/63 2023-09-12 21:51:53.561211803 -0700 +++ /dev/fd/62 2023-09-12 21:51:53.561824746 -0700 @@ -1,4 +1,5 @@ a b +c d -f +e $ diff -i <(sort a.txt) <(sort b.txt) 2a3 > c 4c5 < f --- > e- Is this a good way to create a patch?
comm
diff
$ comm -3 a.txt b.txt c e f $ comm -3 <(sort a.txt) <(sort b.txt) | column -t -s $'\t' --table-columns '==== a.txt ====,==== b.txt ====' ==== a.txt ==== ==== b.txt ==== c e fcommon
$ comm -12 <(sort a.txt) <(sort b.txt) a b d
join
[!NOTE|label:references:]
function join_by {
local d=${1-} f=${2-}
if shift 2; then
printf %s "$f" "${@/#/$d}"
fi
}
-
$ foo=( a "b c" d ) $ printf -v joined '%s,' "${foo[@]}" $ echo "${joined%,}" a,b c,d $ printf -v joined '|,%s,|' "${foo[@]}" $ echo "${joined%,}" |,a,||,b c,||,d,| -
# join by single char $ foo=(a "b c" d) $ bar=$(IFS=, ; echo "${foo[*]}") $ echo "$bar" a,b c,d
alignment
[!TIP]
expand (POSIX)
pr (POSIX)
rs (BSD)
column (BSD)
[!NOTE|label:references:]
$ ( printf "PERM LINKS OWNER GROUP SIZE MONTH DAY HH:MM/YEAR NAME\n"; ls -l | sed 1d ) | column -t
PERM LINKS OWNER GROUP SIZE MONTH DAY HH:MM/YEAR NAME
-rw-r--r-- 1 marslo staff 8 Sep 12 20:10 a.txt
-rw-r--r-- 1 marslo staff 10 Sep 12 19:34 b.txt
$ paste <(echo -e "foo\n\nbarbarbar") <(seq 3) | column -t
foo 1
2
barbarbar 3
$ paste <(echo -e "foo\n\nbarbarbar") <(seq 3) | column -t -s $'\t'
foo 1
2
barbarbar 3
with header
$ paste <(echo -e "foo\n\nbarbarbar") <(seq 3) | column -t -s $'\t' --table-columns '====LEFT====,====RIGHT====' ====LEFT==== ====RIGHT==== foo 1 2 barbarbar 3-
$ echo -e 'a very long string..........\t112232432\tanotherfield\na smaller string\t123124343\tanotherfield\n' | column -t -s $'\t' a very long string.......... 112232432 anotherfield a smaller string 123124343 anotherfield
sort
[!NOTE|label:references:]
sort the last column
awk:
print( $NF" "$0 ) | sort | cut -f2- -d' '$ echo -e '5 5 0 0 622 20\n6 3 2 0 439 8\n5 2 3 0 450 8' 5 5 0 0 622 20 6 3 2 0 439 8 5 2 3 0 450 12 $ echo -e '5 5 0 0 622 20\n6 3 2 0 439 8\n5 2 3 0 450 12' | awk '{print($NF" "$0)}' | sort -k1,1 -n -r -t' ' | cut -f2- -d' ' 5 5 0 0 622 20 5 2 3 0 450 12 6 3 2 0 439 8awk: similar with rev for words
$ echo -e '5 5 0 0 622 20\n6 3 2 0 439 8\n5 2 3 0 450 12' | awk '{ for (i=NF; i>0; i--) printf("%s ",$i); printf("\n")}' | # rev sort -k1,1 -nr -t' ' | awk '{ for (i=NF; i>0; i--) printf("%s ",$i); printf("\n")}' # rev 5 5 0 0 622 20 5 2 3 0 450 12 6 3 2 0 439 8
get lines
get second-to-last line
[!NOTE|label:references:]
sed
$ sed -n 'x;$p' <<\INPUT a b c d INPUT c # or $ echo -e 'a\nb\nc\nd' | sed -n -e '${x;1!p;};h' c # tac + sed $ echo -e 'a\nb\nc\nd' | tac | sed -n '2p' ctail & head
$ echo -e 'a\nb\nc\nd' | tail -2 | head -1 c
get next line by the pattern
$ cat a.txt
1a
2b
3c * (2 lines after `^3c$`)
4d
5e
6f
7g
awk
$ cat a.txt | awk '$0=="3c"{getline; print; getline; print}' 4d 5e $ cat a.txt | awk '/3c/{getline; print; getline; print}' 4d 5eor
$ cat a.txt | awk '/^3c$/ {s=NR;next} s && NR<=s+2' 4d 5eor
$ cat a.txt | awk '{if(a-->0){print;next}} /3c/{a=2}' 4d 5eor get second column of next line of pattern
$ awk '/my.company.com$/{getline; print}' ~/.marslo/.netrc login marslo $ awk '/my.company.com$/{getline; print $2}' ~/.marslo/.netrc marslo
sed
$ cat a.txt | sed -n '/3c/{n;p;n;p}' 4d 5e $ cat a.txt | sed -n '/3c/{N;p;n;p}' 3c 4d 5e
get lines between 2 patterns
[!NOTE|label:reference:]
- How to print lines between two patterns, inclusive or exclusive (in sed, AWK or Perl)?
- Print lines between PAT1 and PAT2
- How to select lines between two marker patterns which may occur multiple times with awk/sed
see also
[!TIP] sample data:
$ cat a.txt 1a 2b 3c * (start) 4d 5e 6f 7g 8h * (end) 9i 10j 11k
awk
- include pattern
$ cat a.txt | awk '/3c/,/8h/' 3c 4d 5e 6f 7g 8h
sed
include all patterns
$ cat a.txt | sed -n '/3c/,/8h/p' 3c 4d 5e 6f 7g 8hexclude both patterns
$ sed -n '/3c/,/8h/{//!p;}' a.txt 4d 5e 6f 7g $ sed -n '/3c/,/8h/{/3c/!{/8h/!p}}' a.txt 4d 5e 6f 7g $ cat a.txt | sed '1,/3c/d;/8h/,$d' 4d 5e 6f 7g $ cat a.txt | sed '/3c/,/8h/!d;//d' 4d 5e 6f 7gexclude single pattern
$ sed -n '/3c/,/8h/{/8h/!p}' a.txt 3c 4d 5e 6f 7g $ sed -n '/3c/,/8h/{/3c/!p}' a.txt 4d 5e 6f 7g 8h
with empty line
[!NOTE] use case : * imarslo : show
topsummary
$ cat a.txt
1a
2b
3c * (start)
4d
5e
6f
* (ending)
7g
8h
9i
10j
11k
$ cat a.txt | sed -n '/3c/,/^$/p'
3c
4d
5e
6f
return first matching pattern
[!TIP]
$ cat sample.crt -----BEGIN CERTIFICATE----- first paragraph -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- second paragraph -----END CERTIFICATE-----
sed
$ cat sample.crt | sed '/-END CERTIFICATE-/q'
-----BEGIN CERTIFICATE-----
first paragraph
-----END CERTIFICATE-----
# or `-n /../p`
# `-n` `p`
# | |
# v v
$ cat sample.crt | sed -n '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p; /-END CERTIFICATE-/q'
-----BEGIN CERTIFICATE-----
first paragraph
-----END CERTIFICATE-----
# or `/../!d`
# no `-n` `!d`
# | |
# v v
$ cat sample.crt | sed '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/!d; /-END CERTIFICATE-/q'
-----BEGIN CERTIFICATE-----
first paragraph
-----END CERTIFICATE-----
awk
$ cat sample.crt | awk '/-BEGIN CERTIFICATE-/{a=1}; a; /-END CERTIFICATE-/{exit}'
-----BEGIN CERTIFICATE-----
first paragraph
-----END CERTIFICATE-----
# or
$ cat sample.crt | awk '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/ {print} /-END CERTIFICATE-/ {exit}'
-----BEGIN CERTIFICATE-----
first paragraph
-----END CERTIFICATE-----
# or
$ cat sample.crt | awk '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/ {print;f=1} f&&/-END CERTIFICATE-/ {exit}'
-----BEGIN CERTIFICATE-----
first paragraph
-----END CERTIFICATE-----
# or
$ cat sample.crt | awk '/-BEGIN CERTIFICATE-/ {f=1} /-END CERTIFICATE-/ {f=0;print;exit} f'
-----BEGIN CERTIFICATE-----
first paragraph
-----END CERTIFICATE-----
return second matching pattern
[!TIP]
$ cat sample.crt -----BEGIN CERTIFICATE----- first paragraph -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- second paragraph -----END CERTIFICATE-----
$ cat sample.crt | awk '/-BEGIN CERTIFICATE-/ && c++, /-END CERTIFICATE-/'
-----BEGIN CERTIFICATE-----
second paragraph
-----END CERTIFICATE-----
xargs
references:
- xargs
- Brainiarc7/xargs-primer-brief.md
- running multiple commands with xargs
- Xargs Command in Linux
- How to Use the Linux xargs Command
- xargs - Construct an argument list and run a command
- Why does the wc utility generate multiple lines with "total"?
$ xargs --show-limits < /dev/null # solution for multiple `total` in $ `git ls-files -z | xargs -0 wc -l`: $ git ls-files -z | wc -l --files0-from=-- xargs split at newlines not spaces
- tips:
--delimiter=delim,-d delim-I{}==-i-n max-args,--max-args=max-args-t,--verbose
complex commands with xargs
[!NOTE|label:references:]
$ echo ip1 ip2 ip3 ... |
fmt -1 |
xargs -i printf 'echo -e "\\n..... {} ....."; /sbin/ping -t1 -c1 -W0 {} | sed "/^$/d"\n' |
xargs -d\\n -n1 bash -c
# so xargs will execute : `echo -e "\n..... {} ....."; /sbin/ping -t1 -c1 -W0 {} | sed "/^$/d"` one by one
- or using
$@$ echo ip1 ip2 ip3 ... | fmt -1 | xargs -n1 bash -c 'echo -e "\n...... $@ ......"; /sbin/ping -t1 -c1 -W0 "$@" | sed '/^$/d'' _
multiple move
$ mkdir ~/backups
$ find /path -type f -name '*~' -print0 | xargs -0 -I % cp -a % ~/backups
# multiple cp
$ find /path -type f -name '*~' -print0 | xargs -0 sh -c 'if [ $# -gt 0 ]; then cp -a "$@" ~/backup; fi' sh
subset of arguments
$ echo {0..9} | xargs -n 2
0 1
2 3
4 5
6 7
8 9
sort all shell script by line number
[!TIP] Pipe
xargsintofind
$ find . -name "*.sh" | xargs wc -l | sort -hr
# better solution
$ find . -name "*.sh" -print0 | wc -l --files0-from=- | sort -hr
diff every git commit against its parent
$ git log --format="%H %P" | xargs -L 1 git diff
running multiple commands with xargs
[!TIP] precondition:
$ cat a.txt a b c 123 ###this is a comment
$ myCommandWithDifferentQuotes=$(cat <<'EOF'
-> echo "command 1: $@"; echo 'will you do the fandango?'; echo "command 2: $@"; echo
-> EOF
-> )
$ < a.txt xargs -I @@ bash -c "$myCommandWithDifferentQuotes" -- @@
command 1: a b c
will you do the fandango?
command 2: a b c
command 1: 123
will you do the fandango?
command 2: 123
command 1: ###this is a comment
will you do the fandango?
command 2: ###this is a comment
or
$ cat a.txt | xargs -I @@ bash -c "$myCommandWithDifferentQuotes" -- @@-
$ while read stuff; do echo "command 1: $stuff"; echo 'will you do the fandango?'; echo "command 2: $stuff"; echo done < a.txt
compress sub-folders
$ find . -maxdepth 1 ! -path . -type d -print0 |
xargs -0 -I @@ bash -c '{ \
tar caf "@@.tar.lzop" "@@" \
&& echo Completed compressing directory "@@" ; \
}'
ping multiple IPs
[!TIP]
-a file, --arg-file=file Read items from file instead of standard input. If you use this option, stdin remains unchanged when commands are run. Otherwise, stdin is redirected from /dev/null.
$ cat a.txt
8.8.8.8
1.1.1.1
$ xargs -L1 -a a.txt /sbin/ping -c 1
PING 8.8.8.8 (8.8.8.8): 56 data bytes
64 bytes from 8.8.8.8: icmp_seq=0 ttl=44 time=82.868 ms
--- 8.8.8.8 ping statistics ---
1 packets transmitted, 1 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 82.868/82.868/82.868/0.000 ms
PING 1.1.1.1 (1.1.1.1): 56 data bytes
64 bytes from 1.1.1.1: icmp_seq=0 ttl=63 time=1.016 ms
--- 1.1.1.1 ping statistics ---
1 packets transmitted, 1 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 1.016/1.016/1.016/0.000 ms
- or
$ echo domain-{1..4}.com | fmt -1 | xargs -L1 ping -c1 -t1 -W0
read by char
$ printf 'mark spitz' | while read -r -n1 c; do printf "[%c]" "$c"; done
[m][a][r][k][][s][p][i][t][z]
find
[!NOTE|label:reference:]
output file name only
# has `./` by default
$ find . -type f
./cfssl-scan
./cfssl-certinfo
./cfssl-bundle
./cfssl
./cfssl-newkey
./multirootca
./mkbundle
./cfssljson
# to show filename only by `-exec basename`
$ find . -type f -exec basename {} -print \;
cfssl-scan
cfssl-certinfo
cfssl-bundle
cfssl
cfssl-newkey
multirootca
mkbundle
cfssljson
# or
$ find . -type f -execdir basename {} ';'
cfssl-scan
cfssl-certinfo
cfssl-bundle
cfssl
cfssl-newkey
multirootca
mkbundle
cfssljson
cat config file in all .git folder
xargs&&cat$ find . -type d -name '.git' -print0 | xargs -0 -I {} cat {}/configfind&&-exec$ find . -type d -name '.git' -exec cat {}/config \;
exec and sed
- change IP address in batch processing
$ find ${JENKINS_HOME}/jobs \ -type f \ -name "config.xml" \ -maxdepth 2 \ -exec sed -i 's/1.2.3./4.5.6./g' {} \; -print
find and rename
$ find -iname "*.sh" -exec rename "s/.sh$/.shell/" {} \; -print
find and exclude
$ find . -regextype posix-egrep -regex ".*\.(js|vue|s?css|php|html|json)$" -and -not -regex ".*/(node_modules|vendor)/.*"
- or
$ find . -regex-type posix-extended -regex ".*def/incoming.*|.*456/incoming.*" -prune -o -print
find && tar
[!TIP] more can be found in imarslo: find and tar
backup all
config.xmlin JENKINS_HOME$ find ${JENKINS_HOME}/jobs -maxdepth 2 -name config\.xml -type f -print | tar czf ~/config.xml.tar.gz --files-from -back build history
$ find ${JENKINS_HOME}/jobs -name builds -prune -o -type f -print | tar czf ~/m.tar.gz --files-from -
find by timestamp
[!NOTE|label:references:]
- Find files newer than a day and copy
How to find the difference in days between two dates?
$ echo $(( ($(date +%s -d 20210131)-$(date +%s -d 20210101))/86400 )) days 30 days # or in `%y%m%d` format $ echo $(( ($(date --date="230301" +%s) - $(date --date="240301" +%s) )/(60*60*24) )) days -366 days
via mtime
[!TIP|label:tricky on
-mtime:]
- Understanding find with atime, ctime, and mtime
+n: for greater than n-n: for less than nn: for exactly n- i.e.:
-mtime -14: less than 14 days, not including 14 days == 13 days ago and less-mtime +14: more than 14 days, not including 14 days == 15 days ago and more- * iMarslo : how many days from timestamps
# get all files since 2023-10-16
$ diff=$(( ($(date --date "24-02-29" +%s) - $(date --date "231016" +%s) )/(60*60*24) ))
$ find . -type f -daystart -mtime -$((diff+1)) -printf "%T+ | %p\n" | sort | wc -l
33
# copy all files modified since 2023-10-16
$ find . -type f -daystart -mtime -$((diff+1)) -exec cp -a --parents -t /path/to/target "{}" \+
# with timezone
$ diff=$(( ($(date -d "2015-03-11 UTC" +%s) - $(date -d "2015-03-05 UTC" +%s)) / (60*60*24) ))
via newermt
[!TIP|label:tips for
-newerXY]
What does newermt mean in find command?
-newerXY reference Compares the timestamp of the current file with reference. The reference argument is normally the name of a file (and one of its timestamps is used for the comparison) but it may also be a string describing an absolute time. X and Y are placeholders for other letters, and these letters select which time belonging to how reference is used for the comparison. a The access time of the file reference B The birth time of the file reference c The inode status change time of reference m The modification time of the file reference t reference is interpreted directly as a time- List of files modified between perticular time period
- How to find files between two dates using "find"?
- find files in data range
$ find ./ -newermt "2016-01-18" ! -newermt '2016-01-19' $ find . -type f -newermt "2014-10-08 10:17:00" ! -newermt "2014-10-08 10:53:00"
$ find . -type f -newermt '2023-10-16 00:00:00' | wc -l
33
# or
$ find . -type f -newermt '16 Oct 2023 00:00:00' | wc -l
33
# or with difference timestamp format
$ find . -type f -newermt "@$(date +%s -d '10/16/2023 0:00:00 PDT')" -printf "%T+ | %p\n" | sort | wc -l
33
# copy all files modified since 2023-10-16
$ find . -type f -newermt '2023-10-16 00:00:00' -exec cp -a --parents -t /path/to/target "{}" \+
inject commands inside find
[!NOTE|label:references:]
$ find -exec bash -c '
print_echo() { printf "This is print_echo Function: %s\n" "$@"; };
print_echo "$@"
' find-bash {} +
printf
[!NOTE|label:references:]
time formats
[!NOTE|label:references:]
printftime formatsfind . -printf "%T<format>\n"
@: unix epocha|A: abbreviated | full weekday (Wed|Wednesday)b/h|B: abbreviated | full month name (Aug|August)m: month :01..12d: day of month :01..31w: day of week01:Monday02:Tuesday
j: day of year :001..366U: week number of the year Sunday as first day of week:00..53W: week number of the year Monday as first day of week:00..53y|Y: last two digits of year | year :00..99|1970..r: time in 12-hour format :hh:mm:ss [AP]M$ find . -type f -printf "\n%Td-%Tm-%TY %Tr %p" | head -1 4-10-2023 02:38:42 AM /Users/marslo/.marslo/.marslorcT: time in 24-hour format :hh:mm:ss.xxxxxxxxxx$ find . -type f -printf "\n%Td-%Tm-%TY %TT %p" | head -1 14-10-2023 02:38:42.5626405780 /Users/marslo/.marslo/.marslorcX: locale time :hh:mm:ss.xxxxxxxxxxc: locale time in ctime format$ find . -type f -printf "\n%Tc %p" | head -1 Sat Oct 14 02:38:42 2023 /Users/marslo/.marslo/.marslorcD: date :mm/dd/yyF: date :yyyy-mm-ddx: locale date :mm/dd/yyR: hour and minute in 24 hour format :HH:MM+: date and time$ find . -printf "%T+ | %p\n" | head -1 2023-10-14+02:38:42.5626405780 | /Users/marslo/.marslo/.marslor-
- center-align
$ find . -printf "%15TA | %p\n" Monday | /Users/marslo/.marslo/bin/iweather Saturday | /Users/marslo/.marslo/.marslorc left-align
$ find . -printf "%-15TA | %p\n" Monday | /Users/marslo/.marslo/bin/iweather Saturday | /Users/marslo/.marslo/.marslorcmixed align
$ find . -type f -printf "%10T+ %-10TA | %m | %p\n" | sort -r | head -2 2023-10-16+20:25:53.5005192040 Monday | 755 | /Users/marslo/.marslo/bin/iweather 2023-10-14+02:38:42.5626405780 Saturday | 755 | /Users/marslo/.marslo/.marslorc # more find . -type d -printf "%d %-30p %-10u %-10g %-5m %T+\n" | sort
- center-align
trim
trim tailing chars
str='1234567890'
awk+rev$ echo $str | rev | cut -c4- | rev 1234567${var:: -x})$ echo ${str:: -3} 1234567
remove leading & trailing whitespace
$ str=" aaaa bbbb "
$ echo "$str" | sed 's:^ *::; s: *$::'
# i.e.:
$ echo .$(echo "$str" | sed 's:^ *::; s: *$::').
.aaaa bbbb.
remove all spaces
$ echo .${str// }. .aaaabbbb.-
$ echo .${str##+([[:space:]])}. .aaaa bbbb . -
$ echo .${str%%+([[:space:]])}. . aaaa bbbb. function in pip
function trim() { IFS='' read -r str; echo "${str}" | sed -e 's/^[[:blank:]]*//;s/[[:blank:]]*$//'; } $ echo ..$(echo " aaa bbb " | trim).. ..aaa bbb..
remove empty lines
[!NOTE|label:references:]
- Delete empty lines using sed
sed
'/^[[:space:]]*$/d''/^\s*$/d''/^$/d'-n '/^\s*$/!p'grep
.-v '^$'-v '^\s*$'-v '^[[:space:]]*$'awk
/./'NF''length''/^[ \t]*$/ {next;} {print}''!/^[ \t]*$/'
# original
$ cal | cat -pp -A
····January·2024····␊
Su·Mo·Tu·We·Th·Fr·Sa␊
····1··2··3··4··5··6␊
·7··8··9·10·11·12·13␊
14·15·16·17·18·19·20␊
21·22·23·24·25·26·27␊
28·29·30·31·········␊
····················␊
# awk 'NF'
$ cal | awk 'NF' | cat -pp -A
····January·2024····␊
Su·Mo·Tu·We·Th·Fr·Sa␊
····1··2··3··4··5··6␊
·7··8··9·10·11·12·13␊
14·15·16·17·18·19·20␊
21·22·23·24·25·26·27␊
28·29·30·31·········␊
# sed '/^\s*$/d'
$ cal | sed '/^\s*$/d' | cat -pp -A
····January·2024····␊
Su·Mo·Tu·We·Th·Fr·Sa␊
····1··2··3··4··5··6␊
·7··8··9·10·11·12·13␊
14·15·16·17·18·19·20␊
21·22·23·24·25·26·27␊
28·29·30·31·········␊
search and replace
[!NOTE|label:reference]
sample code:
str='aa bb cc'
${variable//search/replace}$ shopt -s extglob $ echo ${str//+( )/|} aa|bb|cc-
$ echo "${str//+([[:blank:]])/|}" aa|bb|cc sed
# DO NOT USE "${str}" $ echo ${str} | sed 's: :|:g' aa|bb|cc$ echo "$str" | sed 's:[ ][ ]*:|:g' aa|bb|cc # or $ echo "$str" | sed 's:\s\s*:|:g' aa|bb|cc echo "${string:0:$(( position - 1 ))}${replacement}${string:position}" # or $ sed 's:\s\s*:|:g' <<< "${str}" aa|bb|cc-
$ echo "$str" | tr -s ' ' '|' aa|bb|cc
replace with position
$ string=aaaaa
$ replacement=b
$ position=3
$ echo "${string:0:$(( position - 1 ))}${replacement}${string:position}"
aabaa
- or
$ echo "${string:0:position-1}${replacement}${string:position}" aabaa
check line ending
[!NOTE|label:references:]
- check ascii via terminal
$ man ascii$ cat /usr/share/misc/ascii- How Hexdump works
- ASCII Table
- Newline
OS CHARACTER ENCODING ABBREVIATION HEX DEC ESCAPE SEQUENCE UNIX or Unix-like ASCII LF 0A 10 \n MS-DOS ASCII CR LF 0D 0A 13 10 \r\n Commodore 8-bit machines ASCII CR 0D 13 \r QNX pre-POSIX ASCII RS 1E 30 \036 Acorn BBC and RISC OS ASCII LF CR 0A 0D 10 13 \n\r Atari 8-bit machines ATASCII - 9B 155 - IBM mainframe systems EBCDIC NL 15 21 \025 ZX80 and ZX81 non-ASCII NEWLINE 76 118 -
od -c$ echo 'abc' | od -c 0000000 a b c \n 0000004 $ echo -n 'abc' | od -c 0000000 a b c 0000003hexdump -c$ echo 'abc' | hexdump -c 0000000 a b c \n 0000004 $ echo -n 'abc' | hexdump -c 0000000 a b c 0000003hexdump -C$ echo 'abc' | hexdump -C 00000000 61 62 63 0a |abc.| 00000004 # ^ # | # 0x0a: LF $ echo -n 'abc' | hexdump -C 00000000 61 62 63 |abc| 00000003 $ cat a.txt | hexdump -C # 0x0a # v 00000000 61 61 61 61 0a |aaaa.| 00000005 $ unix2dos a.txt unix2dos: converting file a.txt to DOS format... $ cat a.txt | hexdump -C # 0x0d 0x0a # v v 00000000 61 61 61 61 0d 0a |aaaa..| 00000006 $ cat a.txt | hexdump -c 0000000 a a a a \r \n 0000006 $ file a.txt a.txt: ASCII text, with CRLF line terminatorsvim
$ vim a.txt :%!hexdump -C # or $ vim -c '%!xxd' a.txt
remove the ending '\n'
[!NOTE|label:references:]
- Why should text files end with a newline?
original file
$ cat foo.txt abc efg $ cat -A foo.txt abc$ efg$ $ cat foo.txt | od -c 0000000 a b c \n e f g \n 0000010
-
$ truncate -s -1 foo.txt $ od -c foo.txt 0000000 a b c \n e f g 0000007 -
$ sed -z s/.$// foo.txt | od -c 0000000 a b c \n e f g 0000007 $ sed -z s/\\n$// foo.txt | od -c 0000000 a b c \n e f g 0000007 $ sed -z 's/\n$//' foo.txt | od -c 0000000 a b c \n e f g 0000007 -
$ printf %s "$(< foo.txt)" | od -c 0000000 a b c \n e f g 0000007 -
$ head -c -1 foo.txt | od -c 0000000 a b c \n e f g 0000007 -
$ od -c foo.txt 0000000 a b c \n e f g \n 0000010 $ vim -c "set binary noeol" -c "wq" foo.txt $ od -c foo.txt 0000000 a b c \n e f g 0000007 # or : https://stackoverflow.com/a/39627416/2940319 $ vim -c "set noendofline nofixendofline" -c "wq" foo.txt $ od -c foo.txt 0000000 a b c \n e f g 0000007
add '\n' to line-ending
[!TIP]
- for ssh private key issue:
$ ssh -vT sample.host ... Load key "~/.ssh/id_ed25519": error in libcrypto- references:
check last char in the file
# unqualified key $ tail -c1 ~/.ssh/id_ed25519 -$ tail -c1 ~/.ssh/id_ed25519 | xxd -u -p 2D # qualified key $ tail -c1 ~/.ssh/id_ed25519 $ tail -c1 ~/.ssh/id_ed25519 | xxd -u -p 0A $ tail -c1 ~/.ssh/id_ed25519 | hexdump -v -e '/1 "%02X"' 0Aadd new line
$ [ -n "$(tail -c1 file)" ] && echo >> ~/.ssh/id_ed25519 # or $ [ -z "$(tail -c1 file)" ] || printf '\n' >>file # performance for various solutions $ [ -n "$(tail -c1 file)" ] && printf '\n' >>file 0.013 sec $ vi -ecwq file 2.544 sec $ paste file 1<> file 31.943 sec $ ed -s file <<< w 1m 4.422 sec $ sed -i -e '$a\' file 3m 20.931 sec
fold
check the params valid
available params should be contained by 'iwfabcem'
# case insensitive
param=$( tr '[:upper:]' '[:lower:]' <<< "$1" )
for _p in $(echo "${param}" | fold -w1); do
[[ ! 'iwfabcem' =~ ${_p} ]] && exits='yes' && break
done
insert new line
- insert right after the second match string
DCR
DCR
DCRDCR
DCR
check
DCR$ echo -e "DCR\nDCR\nDCR" | awk 'BEGIN {t=0}; { print }; /DCR/ { t++; if ( t==2) { print "check" } }'
write a file without indent space
$ sed -e 's:^\s*::' > ~/file-without-indent-space.txt < <(echo "items.find ({
\"repo\": \"repo-name\",
\"type\" : \"folder\" ,
\"depth\" : \"1\",
\"created\" : { \"\$before\" : \"4mo\" }
})
")
$ cat ~/file-without-indent-space.txt
items.find ({
"repo": "repo-name",
"type" : "folder" ,
"depth" : "1",
"created" : { "$before" : "4mo" }
})
- or
$ sed -e 's:^\s*::' > find.aql <<-'EOF' items.find ({ "repo": "${product}-${stg}-local", "type" : "folder" , "depth" : "1", "created" : { "${opt}": "4mo" } }) EOF
$ sed -e 's:^\s*::' <<-'EOF'
items.find ({
"repo": "${product}-${stg}-local",
"type" : "folder" ,
"depth" : "1",
"created" : { "${opt}": "4mo" }
})
EOF
items.find ({
"repo": "${product}-${stg}-local",
"type" : "folder" ,
"depth" : "1",
"created" : { "${opt}": "4mo" }
})cat
<< - and <<
This type of redirection instructs the shell to read input from the current source until a line containing only delimiter (with no trailing blanks) is seen. All of the lines read up to that point are then used as the standard input for a command.
The format of here-documents is:
<<[-]word here-document delimiterNo parameter expansion, command substitution, arithmetic expansion, or pathname expansion is performed on word. If any characters in word are quoted, the delimiter is the result of quote removal on word, and the lines in the here-document are not expanded. If word is unquoted, all lines of the here-document are subjected to parameter expansion, command substitution, and arithmetic expansion. In the latter case, the character sequence \ is ignored, and \ must be used to quote the characters \, $, and `.
cat with specific character
$ man tab ... -T, --show-tabs display TAB characters as ^Iother references:
$ cat -A sample.sh
LANG=C tr a-z A-Z <<- END_TEXT$
Here doc with <<$
A single space character (i.e. 0x20 ) is at the beginning of this line$
^IThis line begins with a single TAB character i.e 0x09 as does the next line$
^IEND_TEXT$
$
echo The intended end was before this line$
$ bash sample.sh
HERE DOC WITH <<-
A SINGLE SPACE CHARACTER (I.E. 0X20 ) IS AT THE BEGINNING OF THIS LINE
THIS LINE BEGINS WITH A SINGLE TAB CHARACTER I.E 0X09 AS DOES THE NEXT LINE
The intended end was before this line$ cat -A sample.sh
LANG=C tr a-z A-Z << END_TEXT$
Here doc with <<$
A single space character (i.e. 0x20 ) is at the beginning of this line$
^IThis line begins with a single TAB character i.e 0x09 as does the next line$
^IEND_TEXT$
$
echo The intended end was before this line$
$ bash sample.sh
sample.sh: line 7: warning: here-document at line 1 delimited by end-of-file (wanted `END_TEXT')
HERE DOC WITH <<
A SINGLE SPACE CHARACTER (I.E. 0X20 ) IS AT THE BEGINNING OF THIS LINE
THIS LINE BEGINS WITH A SINGLE TAB CHARACTER I.E 0X09 AS DOES THE NEXT LINE
END_TEXT
ECHO THE INTENDED END WAS BEFORE THIS LINE